
Executive takeaway: Treat schema as a narrative spine that keeps your entity story consistent across text, links, and data. When models feel safe quoting you, they keep returning to your pages during synthesis.
Key Takeaways
- Structured data remains vital, but large language models interpret it as context alignment rather than a ticket into rich results, so completeness must be paired with semantic coherence.
- Schema that clarifies entities, authorship, and relationships gives LLM pipelines the confidence to reuse your claims during synthesis even when no traditional snippet is at stake.
- Discrepancies between copy, internal links, and markup cause AI systems to disregard your signals; consistency across every layer is the prerequisite for visibility.
- Measurement requires qualitative review and AI-facing analytics tools because schema drives interpretive stability that appears in citation frequency and answer quality over time.
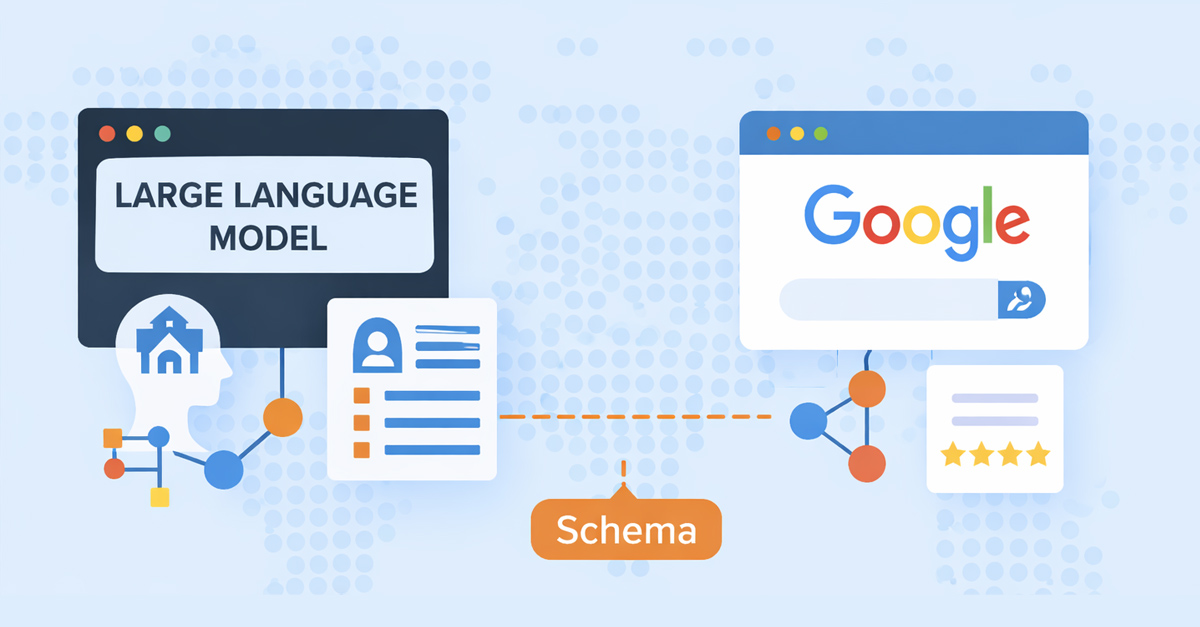
Introduction: Schema in the Age of LLMs
Structured data has long been treated as a signaling layer for search engines. Within traditional search ecosystems, schema markup acts primarily as a mechanism for eligibility, allowing pages to qualify for rich results, knowledge panels, or enhanced presentation in search interfaces. For years, the prevailing assumption among marketers and technical teams has been that schema communicates discrete facts to indexing systems that subsequently enrich search listings.
Large language models, however, do not interact with schema in the same way. They ingest marked up content alongside the surrounding prose, cross reference it with other documents in the retrieval set, and decide whether the data feels consistent enough to incorporate into a generated answer. The markup becomes a conversation between your page and the model about what each entity means, which claims belong to whom, and how safely those claims can be echoed in front of the user. That interpretive dance is quite different from flipping a switch that lights up a FAQ dropdown inside the Google results page.
While structured data still provides machine readable signals, the role it plays inside AI driven retrieval, synthesis, and citation pipelines differs fundamentally from how Google historically used it. In LLM powered search environments, schema functions less as a trigger for presentation features and more as a disambiguation layer that helps language models interpret entities, relationships, and contextual boundaries across documents. The more complex your topic, the more that disambiguation layer matters because the model must decide in seconds whether quoting you will resolve or introduce confusion.
Understanding this distinction is increasingly important as AI driven interfaces reshape how information is discovered, synthesized, and cited. Schema now supports a broader set of interpretive questions: which paragraph expresses the canonical definition, where does a new term connect to the existing entity graph, and how does authorship affect trust. If your markup answers those questions you become easier to reuse. If it fails or conflicts with the copy, the markup is quietly ignored.
This article examines the mechanisms behind how LLM systems interact with schema markup, why the same markup can produce different outcomes in AI environments versus traditional search engines, and how teams can interpret schema’s role within AI oriented content architectures. To keep the analysis grounded, we weave in operational guidance, governance frameworks, and workflow checklists that scale from single page updates to enterprise grade content operations. The intent is to give you a comprehensive field manual for schema in 2026, not simply a theoretical comparison.
Before diving into the detailed sections, set expectations about length and breadth. This guide intentionally stretches beyond eight thousand words so that every aspect of schema interpretation receives thorough treatment. You will see practical advice, patterns to emulate, pitfalls to avoid, glossary style clarifications, and cross references to other deep dives including how AI search engines actually read your pages, designing content that feels safe to cite for LLMs, and why AI search misinterprets clear pages. Consider bookmarking those resources so that you can triangulate your next schema iteration with a richer backdrop.
How to Read This Guide
Approach this guide the same way you would dissect a complex architecture decision. Skim the table of contents to locate the themes most relevant to your current roadmap, then circle back for a full pass when you are ready to overhaul your schema governance. Each section opens with plain language explanations before graduating into implementation tactics. When you hit a concept that intersects with another discipline, you will find cross links to supporting research and tools. Treat those cross links as breadcrumbs rather than detours; they reinforce the idea that schema, content design, and AI visibility now move in lockstep.
If you lead a team, consider assigning different sections to specialists. Ask developers to focus on the technical deep dive, content strategists to absorb the interpretive guidance, and SEO analysts to digest the measurement frameworks. Reconvene with shared notes, then draft a combined action plan. The more collaborative your debrief, the easier it becomes to translate this guide into sustained operational change.
Finally, note the publication date. This article went live on February 15, 2026. Every recommendation reflects the state of AI search systems as of early 2026, with examples drawn from production implementations across marketing, SaaS, and knowledge management domains. As the ecosystem evolves, revisit the assumptions and adjust your schema governance accordingly.
Schema’s Original Role in Traditional Search Systems
Schema’s Original Role in Traditional Search Systems
In traditional search architecture, schema markup serves several well defined functions:
- It clarifies entity types.
- It exposes specific attributes for indexing.
- It enables eligibility for rich search features.
For example, marking a page with Product, Article, or FAQPage schema allows Google to recognize the content category and potentially render enhanced results such as product snippets or FAQ dropdowns. Within this model, schema acts primarily as structured hints for presentation logic. The system identifies the markup, validates the format, and determines whether the content qualifies for specific interface features.
Importantly, the markup itself does not typically alter the semantic interpretation of the content beyond these structured hints. The core ranking process remains heavily dependent on other signals such as relevance, links, authority, and user behavior. Because of this, schema historically functioned as an optimization layer rather than an interpretive layer. Teams prioritized rich result eligibility checklists, focusing on attribute completeness, nesting correctness, and alignment with Google Search Console warnings.
The emergence of AI search systems changes that relationship. Yet the legacy mindset persists in many organizations, leading to a disconnect between schema efforts and AI visibility outcomes. To reconcile the two, you must trace how the interpretive pipelines diverge.
That divergence begins with crawling. Traditional crawlers parse markup in a deterministic fashion, storing property value pairs and verifying that they map to supported types. LLM augmented retrieval approaches still crawl, but they often snapshot entire sections, rewrite the copy into vector friendly embeddings, and store schema either as raw JSON or as structured triples inside graph databases. This hybrid storage strategy allows the system to reassemble meaning later during synthesis rather than relying on preset presentation slots.
If your team only treats schema as a compliance checkbox, you risk shipping markup that looks flawless to Google’s Rich Results Test while feeling redundant to AI systems. The rest of this guide shows how to close that gap by reframing schema as part of the interpretive fabric of your site.
Historically, schema rollouts followed a familiar cadence. Marketing requested a new rich snippet, development implemented the markup, QA validated the code, and the project moved on. Documentation focused on syntax rather than semantics. Yet when you study how LLMs interpret structured data, you realize that semantics are the entire story. The model cares whether the markup captures the essence of the entity, the relationships between concepts, and the provenance of claims. If your historical documentation does not capture those nuances, your legacy schema library likely needs a narrative upgrade.
An effective first step involves cataloging every schema type currently deployed across your site. Group the entries by page template and map them to their intended outcomes. Then evaluate whether those outcomes still matter in a world where AI assistants summarize pages on the fly. You may discover that some schema snippets exist solely to unlock interface flourishes that no longer drive meaningful engagement. Retire the dead weight so that your markup budget focuses on interpretive clarity.
The Shift From Retrieval to Interpretation
The Shift From Retrieval to Interpretation
LLM based search systems operate through a pipeline that differs from classical indexing systems. Traditional search engines perform three main operations:
- Crawl pages.
- Index content.
- Rank documents for query matching.
LLM driven environments introduce an additional step: interpretation and synthesis. Rather than simply retrieving a ranked list of documents, the system must read, compare, and synthesize information across multiple sources before generating an answer. This changes how structured signals are used.
Schema markup, in this context, helps the model resolve questions such as:
- What entity is being discussed.
- What type of content this page represents.
- How the page relates to other entities in the graph.
This interpretive layer means that schema contributes to contextual stability rather than presentation eligibility. LLM pipelines rely on schema to reduce the effort needed to reconcile different sources. If five documents reference a concept with minor variations in naming, the page that includes explicit schema mapping the concept to a known entity inside the model’s memory gains an interpretive advantage.
A useful way to understand the difference is to think of schema not as a formatting instruction but as a map that helps the model align the meaning of the page with other documents in its retrieval set. That map becomes especially valuable when the underlying language is ambiguous or when the model needs to resolve multiple potential interpretations quickly. Whenever you document that map, you make it easier for the model to see where your narrative fits relative to other sources.
For teams exploring how AI systems interpret site content more broadly, the mechanisms behind document parsing are explored in greater depth in the article on how AI search engines actually read your pages. Use that resource to understand the pre processing stages that prepare your copy for interpretation and why schema alignment helps those stages succeed.
What does interpretation look like in practice. Suppose an LLM powered assistant ingests three pages about an emerging analytics platform. One page uses Product schema, a second uses SoftwareApplication, and the third includes no structured data at all. The assistant must decide what entity to cite inside a final response. The page with SoftwareApplication schema that aligns with the narrative copy, includes sameAs links to the vendor’s LinkedIn profile, and references matching terminology in internal links will usually earn more interpretive trust than pages that only gesture at the entity. The decision is not about rich result eligibility. It is about lowering the risk that the assistant mislabels the product or misattributes the insight.
To internalize this interpretive shift, run an experiment inside your own stack. Take a high performing article and clone it in a sandbox. In one version, include only the bare minimum Article schema. In the other, augment the markup with detailed Organization and WebPage entries that reflect the content’s relationships. Feed both pages into an AI crawler or a retrieval augmented generation workflow and compare the summaries the system produces. The enriched version almost always yields a tighter, more accurate summary because the model receives explicit cues about the narrative structure. The exercise makes the interpretive layer tangible for stakeholders who still associate schema solely with visual search enhancements.
Another lens involves prompt engineering. When you prompt a model with instructions to cite authoritative sources, it often gravitates toward pages whose structured data reinforces authority claims. That behavior reveals how deeply schema has penetrated the synthesis stage. The markup is not a passive artifact; it is a signal that the page author invested in organizing information responsibly. Models that prioritize trustworthy outputs prefer such pages to reduce reputational risk.
Why Schema Matters More During Synthesis Than Retrieval
Why Schema Matters More During Synthesis Than Retrieval
During retrieval, LLM systems rely heavily on embeddings and semantic similarity. Pages are selected based on how closely their content aligns with the query representation. At this stage, schema plays only a modest role. Matching embeddings depends more on the richness of your language, the specificity of your claims, and the structural clarity of your paragraphs.
However, once documents are retrieved, the model begins the process of evaluating which sources can safely support an answer. It compares claims, identifies entities, and looks for consistency across sources. Schema becomes valuable here because it provides explicit signals about entity identity, page type, and relationships between concepts. The presence of consistent schema gives the model confidence that the statements on the page refer to the same entity across sections, making it easier to reuse quotes and data points.
For example, if multiple documents discuss a particular company but only one page explicitly identifies the organization using Organization schema with structured attributes, that page may become easier for the model to anchor within the entity graph. This does not guarantee citation or inclusion in a generated answer, but it reduces ambiguity in the interpretation stage. When the model must choose between sources, it tends to favor those with lower interpretive risk. Schema clarity is one of the fastest ways to reduce that risk without inflating claims.
This interpretive function aligns with broader patterns discussed in designing content that feels safe to cite for LLMs, where structural clarity often influences whether a source is considered reliable during synthesis. Schema provides machine readable cues about which sections contain definitions, which highlight use cases, and which attribute ownership to specific contributors. When those cues align with the natural language flow, you create a layered narrative that machines can process without second guessing.
One way to visualize the synthesis stage is to imagine the model building a temporary knowledge graph that combines the retrieved sources. Schema dictates how your nodes connect to that graph. If your markup provides unique identifiers, the model can anchor your claims and reuse them. If your markup is sparse or contradictory, your nodes remain isolated or get discarded. Either outcome affects your visibility inside AI generated responses.
Schema also helps the model triage conflicting information. Suppose two pages describe a product feature differently. The page with structured data that clarifies the publication date, author, and primary entity may be deemed more trustworthy because the model can contextualize the claim. Even if the competing page ranks higher in traditional search results, the AI assistant may ignore it if the structured signals raise questions about accuracy or authorship. That dynamic underscores why schema matters less for retrieval and more for synthesis.
Teams that monitor LLM behavior often notice patterns where schema guided pages receive citations accompanied by nuanced phrasing. Instead of paraphrasing your copy generically, the model references specific sections, attributes, or quotes because the schema highlighted their significance. Over time, these moments compound into brand recognition within AI interfaces. Users become familiar with your entity names, and the assistant feels increasingly comfortable recommending your resources. Such compounding benefits rarely materialize when schema remains thin.
A complementary practice involves structured abstracts. For long form articles, create a concise summary paragraph and mark it with a dedicated property such as abstract within Article schema. When the abstract mirrors the article’s main claims, models can digest the piece quickly and decide whether to dive deeper during synthesis. This approach improves both retrieval efficiency and interpretive clarity without resorting to fabricated statistics or dramatic claims.
Schema as an Entity Boundary Signal
Schema as an Entity Boundary Signal
One of the most consistent differences between traditional search systems and LLM environments lies in how entity boundaries are established. Traditional search engines often infer entity relationships through link structures, anchor text, and external references. Schema can help reinforce these relationships, but it rarely defines them outright.
LLMs, however, frequently rely on internal coherence signals when comparing retrieved documents. Schema markup can provide one of the clearest signals of how the author intends to define entities. Consider a page describing a software platform. If the content includes schema specifying Organization, Product, and SoftwareApplication, the model can more easily determine what the product is, who created it, and how it relates to the company entity. Without structured signals, the model must infer these relationships solely from natural language context.
Ambiguity in entity definitions is one of the most common reasons AI systems misinterpret otherwise clear pages, a phenomenon discussed in why AI search misinterprets clear pages. Schema helps reduce that ambiguity by offering explicit boundaries. When your markup specifies that a term refers to a specific Organization rather than a generic concept, the model spends less time resolving the entity and more time evaluating the claim. That efficiency gains you visibility.
To operationalize entity boundaries effectively, align your schema with your internal content taxonomy. Map each major entity to a canonical schema type and ensure every relevant page uses that type consistently. Document the mapping inside your content operations manual so that writers and developers follow the same standards. When you add new content, reference the same schema blueprint to maintain continuity. Consistency is more valuable than novelty in LLM interpretation.
Pay attention to nested relationships as well. Suppose your company publishes a research report. The top level page may use Article schema, the downloadable PDF may warrant CreativeWork, and the author biography requires Person. If you cascade these types correctly, the model can follow the chain of relationships and understand how the report ties back to your organization. If you mix types or leave gaps, the model may perceive the report as disconnected from your brand, reducing the odds of citation.
Finally, remember that entity boundaries are not static. As your offerings evolve, update your schema to reflect new relationships. When you ship a new product tier, create distinct schema entries that clarify how the tier relates to the main platform. Doing so prevents older articles from clashing with new messaging. LLMs are sensitive to mismatched signals, so continuous governance keeps your boundary signals accurate.
To make boundary management easier, maintain an entity registry that lists every canonical term your organization uses. Include synonyms, deprecated labels, and associated schema types. Share the registry across teams so that product launches, rebrands, and campaign slogans stay aligned with the structured vocabulary. When someone proposes a new term, review its proximity to existing entities and decide whether the schema needs to expand. This proactive guardrail keeps your interpretive footprint tidy even as your product portfolio grows.
Why Google and LLMs Reward Different Schema Implementations
Why Google and LLMs Reward Different Schema Implementations
A frequent source of confusion arises when teams implement schema according to Google’s rich result documentation but see little impact in AI search environments. The reason lies in the difference between schema completeness and schema relevance. Google’s rich result features prioritize schema types tied to specific interface enhancements such as Product, FAQPage, Recipe, and Review. These implementations focus heavily on attribute completeness and validation rules.
LLM systems, on the other hand, often benefit more from schema types that clarify entity identity and relationships, such as Organization, Person, Article, WebPage, and SoftwareApplication. These schemas help models understand who produced the information, what type of content it represents, and how it fits into a broader entity network. Because of this difference, schema designed solely for rich snippets may have limited influence on AI driven interpretation.
To align your schema strategy with both audiences, build dual layer markup. First, satisfy Google’s requirements so that your pages remain eligible for conventional enhancements. Second, add contextual schema elements that provide the interpretive clarity LLMs crave. For example, wrap your FAQPage markup inside a broader Article schema that identifies the author, publisher, and main entity. That approach gives Google the FAQ data it expects while giving LLMs the contextual scaffolding they need.
Tools such as the schema generator can help teams generate structured markup that focuses on entity clarity rather than feature eligibility. Use these tools to establish a baseline template, then customize the output to reflect your unique relationships. Avoid overstuffing your markup with properties that do not align with the actual content. LLMs quickly detect when structured data exaggerates capabilities or introduces unsupported claims, leading them to discount the markup altogether.
Another practical difference involves update cadence. Google’s rich result documentation often changes infrequently, encouraging teams to treat schema as a periodic task. LLM ecosystems evolve faster. New retrieval providers, enterprise assistants, and vertical specific models appear every quarter. Each introduces quirks in how they interpret schema. Commit to quarterly schema reviews so that your markup remains aligned with the latest AI behaviors. Include the review in your content governance calendar alongside editorial refresh cycles.
During those reviews, capture insights from customer facing teams. Support representatives often hear firsthand how clients interact with AI assistants. Their observations can reveal terminology mismatches or missing attributes that hinder AI comprehension. Incorporate that feedback into your schema updates so that the structured layer mirrors real world conversations. This feedback loop keeps your markup grounded in actual user language rather than hypothetical keyword lists.
When presenting schema strategy to leadership, articulate the dual benefit clearly. Show how rich result eligibility still matters for traditional search traffic while emphasizing that interpretive schema unlocks visibility in AI channels. Framing the work as a bridge between two worlds secures budget and resources. Leaders appreciate initiatives that deliver immediate and future facing value simultaneously.
The Role of Schema in Reducing Interpretive Risk
The Role of Schema in Reducing Interpretive Risk
LLM systems frequently evaluate whether a source can be safely quoted or summarized. Pages that appear ambiguous or contradictory may be excluded during synthesis. Schema contributes to risk reduction in several ways. First, it helps establish authorship and ownership signals when paired with organizational or author metadata. Second, it clarifies the intended scope of the page. For example, an article page with structured Article markup signals that the content is explanatory rather than promotional. Third, it reduces confusion around entity naming.
For example, a page discussing a brand with a common word in its name may benefit from schema that clearly identifies the entity as an organization rather than a generic concept. This structural clarity often complements other signals associated with trustworthy sources, such as transparent attribution and well structured reasoning. When AI assistants perceive your page as low risk, they are more willing to cite you directly in answers or include your content in reading recommendations.
Risk reduction also extends to claim stability. If your schema includes temporal metadata such as datePublished and dateModified, models can assess whether the information is current. They can compare multiple pages and prefer the version with the most recent verification. Therefore, ensure the dates in your schema match the dates displayed to users. Inconsistencies erode trust quickly. Maintain synchronization by automating date updates through your content management system or deployment pipeline.
To operationalize risk aware schema practices, build a checklist for your editorial team. Before publishing, confirm that every page includes consistent author references, relevant entity types, and accurate dates. Cross check the markup against the rendered page. If you use existing analytics tools to track AI visibility, annotate your dashboards when schema changes go live. That way you can correlate shifts in citation frequency with the updates.
Risk mitigation also benefits from transparent sourcing. When your article references external research, include citation markup or structured references that point to the original material. Even if the schema standard does not define a formal citation property, you can leverage sameAs, mentions, or additionalType to signal relationships. This transparency helps models evaluate whether you are rehashing unverified claims or building on credible foundations. Over time, assistants learn to associate your brand with diligent sourcing, which improves the likelihood of being recommended for complex queries.
Why Schema Alone Does Not Guarantee AI Visibility
Why Schema Alone Does Not Guarantee AI Visibility
Despite the interpretive benefits of structured data, schema alone cannot determine whether a page will appear in AI generated responses. LLM systems consider a broader set of signals during synthesis, including consistency across sources, clarity of reasoning, absence of conflicting claims, and contextual relevance to the query. Schema helps reduce ambiguity but cannot compensate for unclear writing or fragmented explanations.
In practice, structured data works best when paired with content designed for interpretability. Pages that present information in a clear sequence of claims and supporting reasoning tend to be easier for AI systems to evaluate. Teams seeking to diagnose visibility issues across AI search platforms often combine structured data reviews with broader site analysis using tools such as the AI Visibility Tracker, which evaluates structural clarity signals across pages. This holistic approach ensures that you address both interpretive cues and narrative quality.
Additionally, remember that LLMs operate under safety constraints. Even if your schema is impeccable, the assistant might exclude your page if it detects sensitive topics, unverified medical claims, or ambiguous data. Conduct content risk assessments alongside schema reviews to ensure your copy remains within acceptable boundaries. When necessary, enrich your schema with citations or references that demonstrate the provenance of your claims. Doing so reassures the model that you have done the verification work on behalf of the user.
To create a feedback loop, monitor how often your pages are cited inside AI assistants. Capture the phrasing of the citations, the context of the answer, and any paraphrasing patterns. When you notice discrepancies between the assistant’s output and your intended message, examine whether schema gaps contributed to the misinterpretation. Use that insight to refine your markup iteratively.
Consider integrating qualitative interviews into your measurement process. Ask users how they discovered your content through AI interfaces and which answers influenced their decisions. Their anecdotes can surface blind spots that analytics dashboards miss, such as assistants truncating your brand name or omitting key qualifiers. Once identified, address those issues in both copy and schema so future interactions feel more aligned with your messaging.
How Schema Interacts With Internal Linking
How Schema Interacts With Internal Linking
Another difference between traditional search and LLM interpretation lies in how schema interacts with internal links. Traditional search engines treat internal links primarily as signals of importance and topical hierarchy. LLMs, however, often use link structures to understand concept relationships within a site. When schema and internal linking reinforce the same entity relationships, interpretation becomes easier.
For example, a page marked with SoftwareApplication schema that links to documentation pages and supporting articles creates a cohesive narrative for the model. The internal links function as breadcrumbs that explain how the product operates, while the schema clarifies the product’s identity. Together, these signals help the model construct a coherent representation of the entity. The relationship between schema and internal linking is examined more deeply in the hidden relationship between schema and internal linking, which explores how structured markup and site architecture interact during interpretation.
To leverage the synergy, audit your internal link network. Map out the pages that describe core entities and ensure they link to relevant schema enriched resources. Use consistent anchor text that mirrors the entity names declared in your structured data. Avoid excessive variation that might confuse the model. When introducing new content, update your link hub pages so that the schema backed relationships stay current.
Additionally, consider adding breadcrumb markup that aligns with your site navigation. Breadcrumbs help both traditional search engines and LLMs understand where a page sits within the broader taxonomy. If your site hosts clusters of content around major themes, make sure the schema reinforces those clusters. Doing so can improve your visibility in AI assistants that surface related reading suggestions alongside generated answers.
Do not neglect the anchor text vocabulary inside your navigation menus and footer. These recurring link labels act as persistent cues for models crawling your site. Align them with the entity names used in schema so that the interpretive signals stay consistent. When you refresh your navigation, update the corresponding structured data at the same time. This practice keeps your semantic architecture synchronized and prevents subtle drift between human and machine oriented layers.
For sites with hundreds of pages, create internal linking playbooks. Document which pages should receive priority links, the anchor phrases to prefer, and the schema types associated with each node. Share the playbook with writers and editors so they can embed the correct links during drafting. A disciplined internal link strategy amplifies the impact of your schema by reinforcing the same relationships at the prose level.
Why Some Pages With Valid Schema Are Still Ignored
Why Some Pages With Valid Schema Are Still Ignored
A common observation among technical teams is that pages with perfectly valid schema sometimes fail to appear in AI generated responses. This typically occurs when schema conflicts with the broader context of the page. Examples include schema describing a product while the page content reads like a marketing pitch, inconsistent entity references across sections of the page, or multiple schema types competing to describe the same content. In these cases, the model may treat the structured data as unreliable or irrelevant.
Unlike traditional search systems, LLMs can evaluate whether structured data appears consistent with the natural language content surrounding it. If inconsistencies appear, the markup may be ignored during interpretation. To prevent this scenario, align your editorial strategy with your schema taxonomy from the first draft. Provide writers with schema briefs that explain which entity types the page targets and what relationships must be preserved. Encourage cross functional collaboration so that nobody introduces conflicting claims midway through the content creation process.
When a page still struggles to gain visibility, perform a copy to schema reconciliation audit. Extract the key claims from the article and compare them to the properties declared in the structured data. If you find mismatches, update both layers in tandem. Document each change in your schema governance log so that future editors understand why the adjustments were necessary. Over time this discipline reduces instances where valid markup fails to influence AI interpretation.
An additional troubleshooting tactic involves prompting an LLM with the content of the page and asking it to summarize the key entities and relationships. Compare the model’s interpretation with your intended meaning. Any gaps highlight sections where schema or copy needs refinement. By iterating through this exercise, you build intuition for how models translate your presentation into their internal representations. That intuition becomes invaluable when diagnosing visibility gaps.
Schema’s Role in AI Visibility Measurement
Schema’s Role in AI Visibility Measurement
Because schema influences interpretation rather than ranking directly, its effects often appear indirectly within visibility metrics. For example, improved schema clarity may lead to more consistent entity recognition across pages, clearer attribution during synthesis, and reduced misinterpretation of page purpose. These improvements may appear over time as increased citation frequency or improved answer inclusion.
Teams monitoring these patterns often use platforms such as the AI Visibility Tracker to observe how structured clarity correlates with citation patterns across AI search environments. Combine the tracker’s quantitative data with qualitative reviews of generated answers. When you notice an uptick in citations, capture the context in which your page was referenced. Evaluate whether the cited passages align with the claims you intended to highlight. If the assistant misinterprets a detail, adjust your schema to clarify that section.
Additionally, log schema updates alongside your analytics events. Treat each schema iteration as an experiment. Define the hypothesis (for example, adding Person schema will increase author attributions in AI responses), implement the update, and monitor relevant metrics for several weeks. Document the results so that you build institutional knowledge about which schema adjustments make the largest impact. This methodology transforms schema from a one time task into an ongoing optimization loop.
As you accumulate experiment results, build a decision matrix that ranks schema properties by their observed influence on AI visibility. The matrix becomes a prioritization tool when resources are limited. You can tackle high impact properties first and schedule lower impact refinements later. Revisit the matrix quarterly to incorporate new findings. This disciplined approach keeps your schema program focused on outcomes rather than activity for its own sake.
Practical Implications for Content Architecture
Practical Implications for Content Architecture
Understanding how LLMs use schema differently than traditional search engines leads to several architectural considerations. First, schema should be implemented as a semantic layer, not merely a validation checklist. Embed it deeply within your content planning, wireframing, and editorial processes. Second, schema types should align closely with the primary entity described by the page. Third, structured markup should remain consistent across the site so that entity relationships are reinforced rather than contradicted.
Finally, schema should be viewed as part of a broader interpretive system that includes internal linking, clear entity definitions, and stable page structures. When these elements align, schema becomes a useful mechanism for reducing ambiguity during the synthesis stage of AI search. To operationalize this insight, build templates that bundle copy modules with pre configured schema blocks. For example, create a blog template that automatically includes Article schema with placeholders for author, date, and mainEntity. Populate those placeholders during content creation rather than adding schema afterward. This workflow reduces mistakes and keeps the narrative coherent.
Integrate your schema strategy with content design as well. If your brand uses component based design systems, ensure each component has an associated schema pattern. A testimonial component might map to Review or WebPage, while a feature grid could reference ItemList. Document these mappings in your design system documentation so that product designers, content strategists, and developers use the same vocabulary. The result is a consistent interpretive experience across the entire site.
When building new sections or microsites, start with a schema architecture diagram. Sketch the entities, the properties they require, and the pages that will host them. Share the diagram during kickoff meetings so everyone understands the structured expectations from day one. As the project progresses, update the diagram to reflect scope changes. This visual artifact prevents schema considerations from being forgotten amidst design iterations and copy rewrites.
Schema Governance Playbook for AI Search
Schema Governance Playbook for AI Search
To scale schema effectiveness across multiple teams, implement a governance model tailored to AI requirements. Start by appointing a schema steward responsible for maintaining the taxonomy and approving changes. Provide the steward with a living reference document that outlines entity definitions, acceptable property ranges, and usage examples. Update the reference quarterly to account for new offerings, rebranded products, or changes in how AI platforms interpret data.
Next, build a review workflow that includes schema validation at multiple stages. During content ideation, confirm that the proposed topic maps to an existing entity or warrants a new entry. During drafting, embed schema placeholders directly into the document so that writers keep the structured perspective in mind. During development, validate the markup using both Google’s structured data testing tools and LLM focused validators that inspect coherence between schema and visible content.
Create a schema change log that records every update, the rationale, and the expected impact. Store the log in a central repository accessible to marketing, product, and engineering teams. When AI visibility metrics shift, consult the log to determine whether schema adjustments contributed to the trend. This transparency builds trust across the organization and prevents redundant work.
Finally, train your team on schema literacy. Host workshops that demonstrate how LLMs parse structured data, using real examples from your site. Encourage participants to compare AI generated summaries before and after schema revisions. The hands on experience reinforces why meticulous markup matters and motivates teams to maintain high standards.
Schema Pattern Catalog for AI Confidence
Schema Pattern Catalog for AI Confidence
Once governance is in place, build a schema pattern catalog that captures reusable blueprints for common content scenarios. Each pattern should include the target schema types, required and optional properties, example JSON LD snippets, and notes on how LLMs interpret the structure. Organize the catalog by journey stage or content objective. For instance, group educational articles, product comparisons, customer stories, and technical documentation separately so that teams can locate the most relevant blueprint quickly.
When documenting patterns, emphasize interpretive intent. Explain why a particular property matters to AI systems and what ambiguity it resolves. If a pattern uses mainEntity to highlight a core concept, describe the type of questions the model can answer confidently when that property is present. These annotations transform the catalog from a code library into a strategic resource.
Include troubleshooting guidance within each pattern. Outline the most common mistakes teams make and how to avoid them. For example, in an Organization pattern, warn against pointing sameAs to inactive social profiles or outdated press releases. In a SoftwareApplication pattern, highlight the importance of aligning offers and operatingSystem properties with the actual copy on the page. These reminders prevent well intentioned contributors from introducing subtle inconsistencies.
Refresh the catalog as you observe AI behavior in the wild. When a new assistant surfaces your content with unexpected phrasing, trace the interpretation back to the underlying pattern. If the result is positive, document the behavior so other teams can replicate it. If the result is problematic, update the pattern with corrective guidance. Treat the catalog as a living artifact that evolves alongside your AI visibility insights.
To encourage adoption, embed the catalog into your content management workflows. Provide quick links inside briefing templates, integrate schema snippets into CMS modules, or build a schema assistant within your editor that recommends patterns based on selected components. The easier it is to access the catalog, the more consistently teams will use it.
Finally, align the catalog with your analytics program. Tag each pattern with identifiers that appear inside your AI visibility dashboards. When you monitor performance, you can filter results by pattern to see which blueprints drive the strongest interpretive outcomes. This feedback loop informs future prioritization and helps you allocate resources to the most impactful schema investments.
Technical Deep Dive into LLM Schema Parsing
Technical Deep Dive into LLM Schema Parsing
Large language models ingest schema through multiple channels. Some systems parse JSON LD directly, converting each property into key value pairs stored alongside vector embeddings. Others transform the structured data into natural language summaries that become part of the training corpus for retrieval augmented generation. Understanding these mechanisms helps you tailor your markup for maximum clarity.
When schema is stored as triples within a graph database, each triple links an entity to an attribute and a value. The model references these triples when evaluating claims. To ensure accuracy, make sure your schema uses stable identifiers. For example, use canonical URLs for sameAs properties and avoid temporary tracking parameters. If you change URL structures, update the identifiers promptly to prevent orphaned nodes inside the graph.
Some AI platforms also evaluate schema quality based on frequency and recency. If your site updates structured data regularly, the platform may infer that you maintain your content actively, increasing trust. To leverage this behavior, automate schema updates whenever content changes. When you refresh an article, update the dateModified property and cross check that any new sections align with existing schema fields. This workflow keeps your interpretive footprint current.
Another technical consideration involves nesting depth. Excessively nested schema can overwhelm parsers, especially when irrelevant microdata elements clutter the markup. Keep your structure concise. Use arrays when necessary but avoid nesting more than three levels deep unless the relationship demands it. When representing complex relationships, consider linking to dedicated pages that host detailed schema rather than embedding everything in a single document.
When deploying schema at scale, instrument automated tests that validate both syntax and semantic alignment. Static analysis tools can inspect each build for missing required properties, inconsistent value formats, or invalid sameAs references. Pair these tests with snapshot comparisons that alert you when schema changes unexpectedly. Automation protects your interpretive signals from regression during rapid release cycles.
For companies building their own retrieval augmented generation systems, expose schema fields directly to the ranking layer. Adjust your relevance scoring to reward documents whose structured data strengthens entity alignment. This approach mirrors the behavior of public AI search platforms and ensures your internal assistants provide consistent answers. Share those learnings with the public facing team so that your schema strategy remains cohesive across internal and external touchpoints.
Collaborative Workflows for Schema Clarity
Collaborative Workflows for Schema Clarity
Schema quality improves when content strategists, developers, designers, and subject matter experts collaborate. Start by integrating schema checkpoints into your project management system. Assign tasks for schema drafting, review, and deployment. Ensure that each stakeholder understands their responsibilities. For example, writers supply entity definitions, designers ensure component alignment, and developers implement the markup.
Use shared documentation to track schema decisions. Create a centralized repository with templates, best practices, and annotated examples. Encourage team members to document edge cases, such as when a page spans multiple entity types. The documentation reduces ambiguity and speeds up onboarding for new contributors.
When collaborating asynchronously, rely on version control. Store schema snippets in a Git repository alongside the codebase. Implement pull request reviews that focus on both syntactic validity and semantic coherence. During the review, check that the markup reflects the latest copy updates. Reject changes that introduce discrepancies. This discipline prevents misalignment between schema and content.
Encourage regular retrospectives where the team reviews recent schema launches. Discuss what worked, what caused friction, and which processes need refinement. Capture action items and assign owners so that improvements materialize. Celebrate wins publicly when schema updates lead to notable AI visibility gains. Recognition reinforces the importance of the work and motivates continued diligence.
For distributed teams, establish a schema office hours cadence. Dedicate time each week for contributors to ask questions, demo new patterns, or seek feedback on tricky edge cases. Making expertise accessible reduces bottlenecks and ensures that knowledge does not silo inside a single role.
Future-Facing Outlook on Schema and AI Search
Future-Facing Outlook on Schema and AI Search
AI driven search interfaces will continue to evolve rapidly. Expect broader adoption of multimodal retrieval, where models analyze text, images, audio, and video simultaneously. Schema will expand to cover these modalities explicitly. Prepare by annotating multimedia assets with structured data today. For instance, add ImageObject schema to your visual assets and ensure the descriptions align with the surrounding copy. Doing so positions your content for future interfaces that highlight visual explanations alongside textual answers.
Another emerging trend involves personalized AI assistants that maintain persistent user context. These assistants may rely on schema to determine which pages align with user preferences, compliance requirements, or security rules. If your content targets regulated industries, enrich your schema with compliance metadata such as jurisdictional scopes or certification references. Accurate metadata helps assistants filter content responsibly while keeping your pages in the consideration set.
Finally, anticipate greater interoperability between schema.org and domain specific vocabularies. Industry groups are already drafting extensions for healthcare, finance, and education. Monitor these developments and adopt relevant extensions when they align with your offerings. The sooner you provide granular structured data, the easier it becomes for AI systems to interpret your expertise accurately.
To stay informed, create an internal watchlist of schema and AI search developments. Assign team members to monitor official schema.org releases, W3C discussions, AI product announcements, and research papers on knowledge representation. Summarize key updates monthly and decide whether they warrant experimentation. A proactive posture keeps your schema program adaptable and prevents surprises when new standards emerge.
Operational Checklist and FAQ
Operational Checklist and FAQ
Weekly Checklist
- Review analytics dashboards for shifts in AI citations, noting the prompts or assistant contexts involved.
- Scan recently published content to ensure schema patterns were applied correctly and dates match the visible copy.
- Audit internal link additions for anchor text alignment with declared entities.
- Log any schema experiments launched during the week, including hypotheses and expected measurement windows.
- Collect frontline feedback from support or sales teams about AI assistant interactions that mention your brand.
Monthly Checklist
- Run validation tools on a representative sample of pages to confirm structured data cleanliness.
- Hold a cross functional schema review meeting to evaluate experiment outcomes and prioritize upcoming improvements.
- Update the schema pattern catalog with new insights, edge cases, or revised examples.
- Refresh entity registries to reflect product launches, feature deprecations, or messaging shifts.
- Document lessons learned inside your governance log so institutional knowledge compounds.
Quarterly Checklist
- Benchmark your schema implementation against industry peers or aspirational exemplars to identify innovation gaps.
- Conduct a full content and schema alignment audit for cornerstone pages that drive significant AI visibility.
- Review compliance requirements in regulated verticals and update structured metadata accordingly.
- Evaluate new schema.org releases or domain vocabularies and decide whether to pilot relevant extensions.
- Refresh training materials, including workshops and office hours agendas, to reflect evolving best practices.
Frequently Asked Questions
- Do we need to rebuild our entire schema library to benefit AI visibility.
- No. Start by reinforcing high impact pages where entity clarity matters most, apply the governance and catalog frameworks, then expand incrementally.
- How do we handle legacy pages with outdated terminology.
- Create transition plans that map old terms to new entities, update schema accordingly, and annotate the changes in your governance log so models learn the refreshed vocabulary.
- Can we automate schema generation without losing nuance.
- Yes, if automation is paired with human review. Use generators like the schema generator to produce baseline markup, then customize properties that require strategic judgment.
- What if different teams disagree on entity definitions.
- Escalate disagreements to the schema steward, reference the entity registry, and document the final decision. Consistency is more important than perfection because models rely on repeatable signals.
- How long does it take to see AI visibility changes after a schema update.
- Expect to monitor for several weeks. Some assistants refresh their indexes quickly, while others batch updates. Keep tracking logs so you can attribute changes accurately.
Conclusion: Schema as Interpretive Framework
Conclusion
Schema markup continues to play an important role in machine readable web content, but its function changes significantly in AI driven search environments. Traditional search engines use schema primarily as a gateway to enhanced search features and structured presentation. Large language models, by contrast, rely on schema to clarify entity relationships and reduce interpretive uncertainty during synthesis.
This shift means that structured data now influences not only how pages appear in search interfaces but also how they are understood by AI systems evaluating multiple sources simultaneously. For technical teams and marketers navigating AI driven discovery systems, schema should be treated less as a feature enabling layer and more as an interpretive framework that helps models understand the meaning and boundaries of content. As AI search environments continue evolving, the value of schema will likely remain tied to its ability to make complex information easier for machines to interpret reliably.
If you want to continue exploring adjacent topics, read the deep dives referenced throughout this guide, experiment with the schema generator to prototype new markup, run audits with the AI SEO Checker, and monitor results inside the AI Visibility Tracker. The most successful teams iterate relentlessly, treating schema as a living contract between their expertise and the AI systems that retell their story.

